- در این بخش
- جیسون ساده و الگوی سیفون
- تجزیه و تحلیل بازار بیت کوین و اتریوم - 26. 02. 2023
- چگونه بیت کوین معامله کنیم
- شاخص و استراتژی های SAR پارابولیک
- برنامه مدیر پول ما.
- کارت تاروت مرد حلق آویز شده به معنای در وضعیت عمودی و معکوس
- پارادوکس یک چکش - مسیرهای حرکتی را به مهارت های سخت و نرم می اندازد
- Solana اوج های تازه تمام وقت را ضبط می کند ، Sol به ده دارایی Crypto برتر توسط CAP بازار می پیوندد
- تعریف قیمت گذاری نفوذ ، مثال ها و نحوه استفاده از آن

آخرین مطالب
امکانات وب



در پست های قبلی ، من بحث کرده ام که چگونه می توانیم شبکه های عصبی را با استفاده از backpropagation با تبار شیب آموزش دهیم. یکی از مهمترین چیزهای اصلی برای آموزش یک شبکه عصبی ، میزان یادگیری برای نزول شیب است. به عنوان یک یادآوری ، این پارامتر به منظور به حداقل رساندن عملکرد از دست دادن شبکه ، میزان به روزرسانی وزن ما را مقیاس می دهد.
اگر نرخ یادگیری شما خیلی پایین تنظیم شود ، آموزش بسیار آهسته پیشرفت می کند زیرا به روزرسانی های بسیار ریز و درشتی در وزنهای موجود در شبکه خود می پردازید. با این حال ، اگر نرخ یادگیری شما خیلی زیاد باشد ، می تواند باعث ایجاد رفتار واگرا نامطلوب در عملکرد ضرر شما شود. من این موارد را در زیر تجسم می کنم - اگر این تصاویر را برای تفسیر سخت می دانید ، توصیه می کنم بخش اول را در پست من در مورد نزول شیب بخوانید.

بنابراین چگونه می توانیم نرخ یادگیری بهینه را پیدا کنیم؟
کامل! من حدس می زنم کار من در اینجا انجام شده است.
(با خواندن آن موضوع پس از اتمام این پست ، خود را طنز کنید.)
چشم انداز از دست دادن یک شبکه عصبی (در زیر تجسم شده) تابعی از مقادیر پارامتر شبکه است که "خطا" مرتبط با استفاده از پیکربندی خاص مقادیر پارامتر هنگام انجام استنباط (پیش بینی) در یک مجموعه داده معین را تعیین می کند. این چشم انداز ضرر حتی برای معماری های شبکه بسیار مشابه می تواند کاملاً متفاوت به نظر برسد. تصاویر زیر از یک مقاله است که چشم انداز ضرر شبکه های عصبی را تجسم می کند ، که نشان می دهد چگونه اتصالات باقیمانده در یک شبکه می تواند یک توپولوژی از دست دادن صاف تر را به همراه داشته باشد.
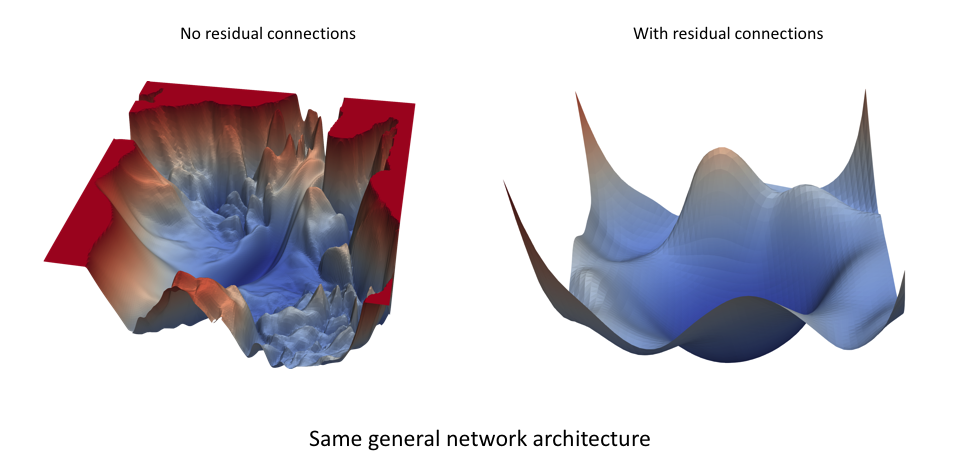
اعتبار تصویر
میزان یادگیری بهینه به توپولوژی چشم انداز ضرر شما بستگی دارد ، که به نوبه خود به معماری مدل و مجموعه داده شما بستگی دارد. در حالی که استفاده از نرخ یادگیری پیش فرض (یعنی پیش فرض های تعیین شده توسط کتابخانه یادگیری عمیق شما) ممکن است نتایج مناسبی را ارائه دهد ، شما اغلب می توانید با جستجوی نرخ یادگیری بهینه ، عملکرد را بهبود بخشیده یا سرعت بخشید. امیدوارم در بخش بعدی ببینید که این کار کاملاً آسان است.
یک رویکرد سیستماتیک برای یافتن نرخ یادگیری بهینه
در نهایت ، ما یک نرخ یادگیری را دوست داریم که نتیجه آن کاهش شدید در از دست دادن شبکه است. ما می توانیم این کار را با انجام یک آزمایش ساده مشاهده کنیم که در آن به تدریج میزان یادگیری را بعد از هر مینی دسته ای افزایش می دهیم و ضرر را در هر افزایش ضبط می کنیم. این افزایش تدریجی می تواند در مقیاس خطی یا نمایی باشد.
برای نرخ یادگیری که خیلی پایین است ، ممکن است ضرر کاهش یابد ، اما با سرعت بسیار کم عمق. هنگام ورود به منطقه بهینه یادگیری ، افت سریع عملکرد از دست دادن را مشاهده خواهید کرد. افزایش نرخ یادگیری بیشتر باعث افزایش ضرر خواهد شد زیرا به روزرسانی های پارامتر باعث از بین رفتن "گزاف گویی در اطراف" و حتی واگرایی از حداقل می شوند. به یاد داشته باشید ، بهترین نرخ یادگیری با شدیدترین افت ضرر همراه است ، بنابراین ما عمدتاً علاقه مند به تجزیه و تحلیل شیب طرح هستیم.
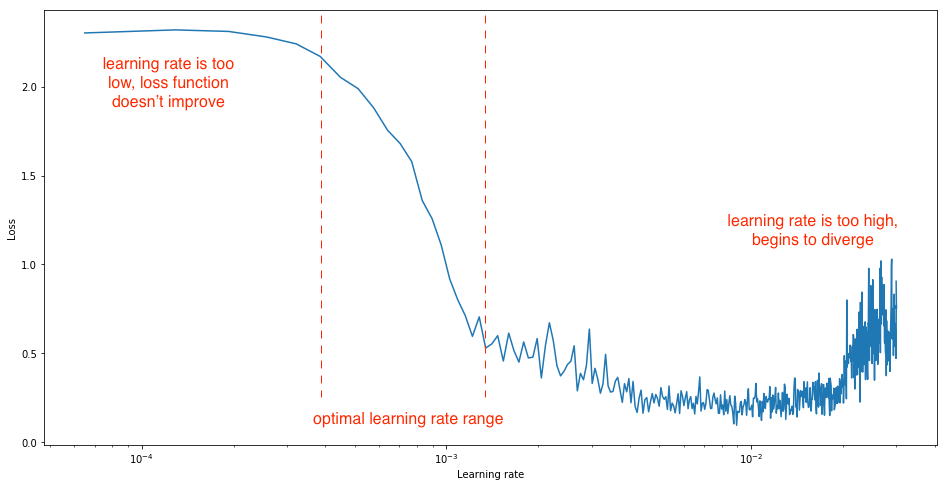
شما باید دامنه مرزهای نرخ یادگیری خود را برای این آزمایش تنظیم کنید به گونه ای که هر سه مرحله را مشاهده می کنید ، و این باعث می شود که محدوده بهینه برای شناسایی باشد.
این تکنیک توسط لسلی اسمیت در نرخ یادگیری چرخه ای برای آموزش شبکه های عصبی ارائه شده و توسط جرمی هوارد در دوره Fast. ai تبشیر شده است.
تنظیم برنامه ای برای تنظیم میزان یادگیری خود در طول آموزش
یکی دیگر از تکنیک های متداول ، که به عنوان بازپرداخت نرخ یادگیری شناخته می شود ، توصیه می کند با نرخ یادگیری نسبتاً بالا شروع شود و سپس به تدریج نرخ یادگیری را در طول آموزش کاهش دهد. شهود پشت این رویکرد این است که ما می خواهیم به سرعت از پارامترهای اولیه به طیف وسیعی از مقادیر پارامتر "خوب" منتقل شویم اما پس از آن می خواهیم یک نرخ یادگیری به اندازه کافی کوچک باشد که بتوانیم قسمتهای عمیق تر ، اما باریک تر را کشف کنیمعملکرد از دست دادن "(از یادداشت های CS231N کارپارتی). اگر در حال تصویربرداری از آنچه من فقط به آن اشاره کردم ، به یاد بیاورید که بیش از حد بالایی از نرخ یادگیری می تواند باعث شود تا به روزرسانی پارامتر "پرش از روی" حداقل ایده آل و به روزرسانی های بعدی منجر به ادامه همگرایی پر سر و صدا در منطقه عمومی شود. از حداقل ، یا در موارد شدیدتر ممکن است منجر به واگرایی از حداقل شود.
محبوب ترین شکل بازپرداخت نرخ یادگیری ، پوسیدگی مرحله ای است که در آن میزان یادگیری پس از تعداد مشخصی از دوره های آموزشی کاهش می یابد.
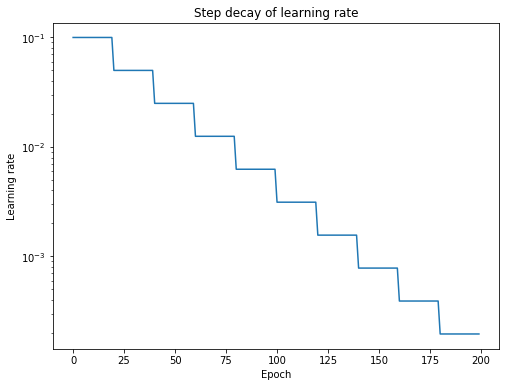
به طور کلی ، ما می توانیم ثابت کنیم که تعریف برنامه نرخ یادگیری که در آن میزان یادگیری در طول آموزش طبق برخی از قانون مشخص شده به روز می شود ، مفید است.
نرخ یادگیری چرخه ای
در مقاله قبلاً ذکر شده ، میزان یادگیری چرخه ای برای آموزش شبکه های عصبی ، لسلی اسمیت یک برنامه نرخ یادگیری چرخه ای را پیشنهاد می کند که بین دو مقدار محدود متفاوت است. برنامه اصلی نرخ یادگیری (تجسم در زیر) یک قانون به روزرسانی مثلثی است ، اما وی همچنین به استفاده از یک به روزرسانی مثلثی در رابطه با پوسیدگی چرخه ای ثابت یا پوسیدگی چرخه ای نمایی اشاره می کند.
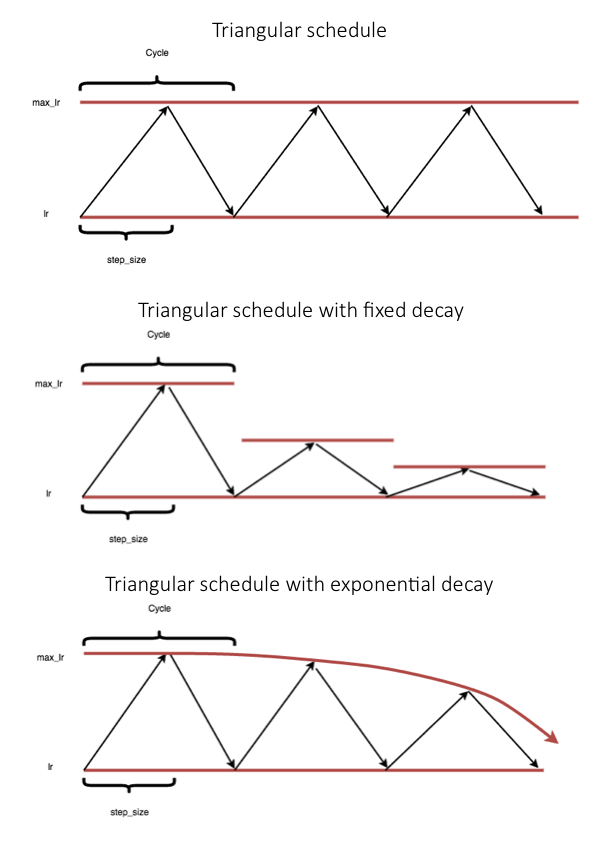
اعتبار تصویر
توجه: در پایان این پست ، کد را برای اجرای این برنامه نرخ یادگیری ارائه می دهم. بنابراین ، اگر به درک فرمولاسیون ریاضی اهمیتی نمی دهید می توانید از این بخش گذشته باشید.
ما می توانیم برنامه کلی را به عنوان بنویسیم
جایی که $ x $ به عنوان تعریف شده است
و چرخه $ $ را می توان به صورت محاسبه کرد
که در آن $ eta_<min>$ و $ eta_<max>$ محدوده نرخ یادگیری ما را تعریف می کند ، $ تکرار $ تعداد مینی دسته های تکمیل شده را نشان می دهد ، $ Stepize $ نیمی از طول چرخه را تعریف می کند. تا آنجا که من می توانم جمع کنم ، 1-X $ باید همیشه مثبت باشد ، بنابراین به نظر می رسد عملکرد $ $ $ کاملاً ضروری نیست.
برای اینکه چگونه این معادله کار می کند ، بیایید به تدریج آن را با تجسم بسازیم. برای تصاویر زیر ، به روزرسانی مثلثی برای 3 چرخه کامل با اندازه پله 100 تکرار نشان داده شده است. به یاد داشته باشید ، یک تکرار با یک مینی دسته آموزش مطابقت دارد.
مهمتر از همه ، ما می توانیم "پیشرفت" خود را در حین آموزش از نظر نیم چرخه که انجام داده ایم ، ایجاد کنیم. ما پیشرفت خود را از نظر نیم چرخه و نه چرخه کامل اندازه گیری می کنیم تا بتوانیم تقارن را در یک چرخه بدست آوریم (با ادامه خواندن ، این باید واضح تر شود).
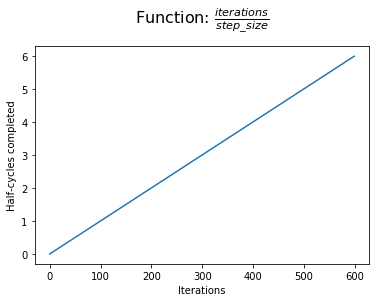
در مرحله بعد ، ما پیشرفت نیم چرخه خود را با تعداد نیم چرخه که در پایان چرخه فعلی تکمیل می شود ، مقایسه می کنیم. در ابتدای چرخه ، ما دو چرخه نیمه تمام وجود نداریم. در پایان یک چرخه ، این مقدار به صفر می رسد.
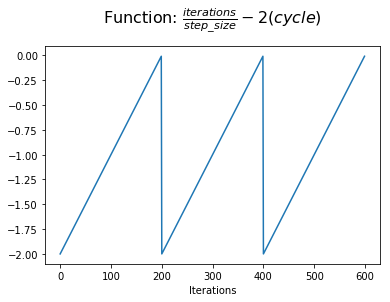
در مرحله بعد ، ما 1 به این مقدار اضافه خواهیم کرد تا عملکردی که در محور y متمرکز شده باشد ، تغییر دهیم. اکنون ما پیشرفت خود را در یک چرخه با اشاره به نقطه نیمه چرخه نشان می دهیم.
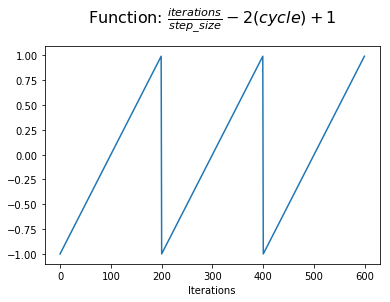
در این مرحله ، ما می توانیم مقدار مطلق را برای دستیابی به شکل مثلثی در هر چرخه بدست آوریم. این ارزشی است که ما به $ x $ اختصاص می دهیم.
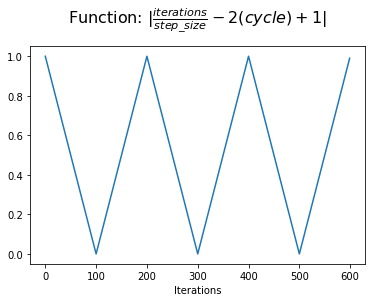
با این حال ، ما دوست داریم که برنامه نرخ یادگیری ما از مقدار minumum شروع شود و در وسط یک چرخه به حداکثر مقدار افزایش یابد و سپس به حداقل مقدار کاهش یابد. ما می توانیم این کار را با محاسبه 1-X $ $ انجام دهیم.
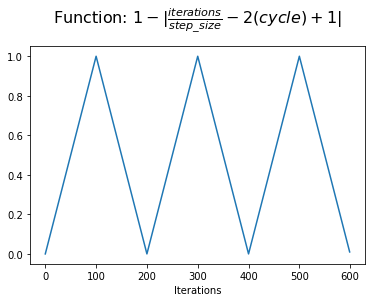
اکنون ما مقداری داریم که می توانیم با اضافه کردن بخشی از محدوده نرخ یادگیری به حداقل نرخ یادگیری (که به عنوان نرخ یادگیری پایه نیز گفته می شود) برای تعدیل نرخ یادگیری استفاده کنیم.
اسمیت می نویسد ، فرض اصلی دلیل منطقی برای نرخ یادگیری چرخه ای (بر خلاف یکی که فقط کاهش می یابد) این است که "افزایش نرخ یادگیری ممکن است اثر منفی کوتاه مدت داشته باشد و در عین حال به یک اثر مفید طولانی مدت دست یابد."در واقع ، مقاله وی شامل چندین نمونه از تکامل عملکرد از دست دادن است که به طور موقت به ضررهای بالاتر منحرف می شود و در نهایت در مقایسه با یک معیار یادگیری ثابت ، به ضرر کمتری همگرا می شود.
برای به دست آوردن شهود در مورد اینکه چرا این اثر کوتاه مدت می تواند تأثیر مثبت طولانی مدت داشته باشد ، درک ویژگی های مطلوب حداقل همگرا ما مهم است. در نهایت ، ما دوست داریم شبکه ما از داده ها به روشی که داده های غیب را تعمیم می دهد ، بیاموزیم. علاوه بر این ، شبکه ای با خصوصیات عمومی سازی خوب باید به این معنا که تغییرات کوچک در پارامترهای شبکه باعث ایجاد تغییرات شدید در عملکرد نمی شود ، قوی باشد. با توجه به این نکته ، این حس می کند که حداقل تیز منجر به تعمیم ضعیف می شود زیرا تغییرات کوچک در مقادیر پارامتر ممکن است منجر به از دست دادن شدید شود. با اجازه افزایش نرخ یادگیری ما در بعضی مواقع ، می توانیم از مینیمای تیز "پرش" کنیم که به طور موقت باعث افزایش ضرر ما می شود اما در نهایت ممکن است منجر به همگرایی در حداقل مطلوب تر شود.
توجه: اگرچه "حداقل مسطح برای تعمیم خوب" به طور گسترده ای پذیرفته شده است ، اما می توانید یک ضد استدلال خوب را در اینجا بخوانید.
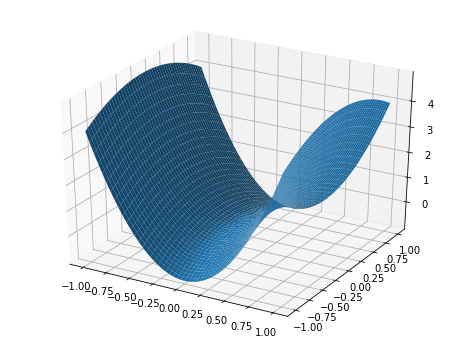
علاوه بر این ، افزایش نرخ یادگیری همچنین می تواند "عبور سریعتر از فلات نقطه زین" را فراهم کند. همانطور که در تصویر زیر مشاهده می کنید ، شیب ها می توانند در یک نقطه زین بسیار کوچک باشند. از آنجا که به روزرسانی های پارامتر تابعی از شیب هستند ، این منجر به بهینه سازی ما می شود که اقدامات بسیار ناچیزی را انجام می دهد. افزایش نرخ یادگیری در اینجا می تواند مفید باشد تا از گیر شدن بیش از حد در یک نقطه زین جلوگیری شود.
اعتبار تصویر (با اصلاح)
توجه: یک نکته زین ، به تعریف ، یک نکته مهم است که در آن برخی از ابعاد حداقل محلی را مشاهده می کنند در حالی که ابعاد دیگر حداکثر محلی را مشاهده می کنند. از آنجا که شبکه های عصبی می توانند هزاران یا حتی میلیون ها پارامتر داشته باشند ، بعید به نظر می رسد که ما حداقل محلی واقعی را در تمام این ابعاد مشاهده کنیم. نقاط زین بسیار بیشتر به احتمال زیاد رخ می دهد. هنگامی که من به "مینیما تیز" اشاره کردم ، واقع بینانه باید یک نقطه زین را تصویر کنیم که حداقل ابعاد بسیار شیب دار باشد در حالی که حداکثر ابعاد بسیار گسترده است (همانطور که در شکل زیر نشان داده شده است).
نزول شیب تصادفی با شروع مجدد گرم (SGDR)
یک رویکرد چرخه ای مشابه به عنوان نزول گرادیان تصادفی با شروع مجدد گرم شناخته می شود که در آن یک برنامه بازپرداخت تهاجمی با "راه اندازی مجدد" دوره ای به نرخ یادگیری اصلی شروع می شود.

ما می توانیم این برنامه را به عنوان بنویسیم
جایی که $ $ نرخ یادگیری در timestep $ t $ (افزایش هر مینی دسته) ، $<eta_<max>^i>$ و $<eta_<min>^i>$ دامنه نرخ یادگیری مورد نظر را تعریف کنید ، $ t_ $ تعداد دوره ها را از آخرین راه اندازی مجدد نشان می دهد (این مقدار در هر تکرار محاسبه می شود و بنابراین می تواند مقادیر کسری را به خود اختصاص دهد) و $ t_ $ تعداد دوره های یک چرخه را تعریف می کندبشربیایید سعی کنیم این معادله را خراب کنیم.
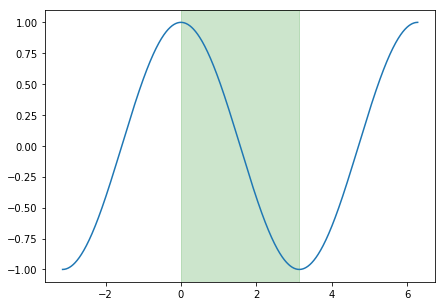
This aealing schedule relies on the cosine function, which varies between -1 and 1. $>>$ قادر به گرفتن مقادیر بین 0 تا 1 است ، که ورودی عملکرد کسین ما است. منطقه مربوطه از عملکرد كسین در زیر به رنگ سبز برجسته شده است. با افزودن 1 ، عملکرد ما بین 0 تا 2 متفاوت است ، که سپس با $ frac $ مقیاس می شود تا اکنون بین 0 تا 1 متفاوت باشد. بنابراین ، ما به سادگی حداقل نرخ یادگیری را می گیریم و بخشی از محدوده نرخ یادگیری مشخص شده را اضافه می کنیم($<eta_<max>^i - eta_<min>^i>$). از آنجا که این عملکرد از 1 شروع می شود و به 0 کاهش می یابد ، نتیجه یک نرخ یادگیری است که از حداکثر دامنه مشخص شده شروع می شود و به حداقل مقدار می رسد. پس از رسیدن به پایان یک چرخه ، $ t_ $ به 0 بازنشانی می شود و با حداکثر نرخ یادگیری شروع می کنیم.
نویسندگان خاطرنشان می کنند که این برنامه نرخ یادگیری می تواند بیشتر با:
- با پیشرفت آموزش ، چرخه را طولانی تر کنید.
- پوسیدگی $<eta_<max>^i>$ و $<eta_<min>^i>$ بعد از هر چرخه.
با افزایش چشمگیر نرخ یادگیری در هر راه اندازی مجدد ، ما اساساً می توانیم از حداقل محلی خارج شویم و به کاوش در چشم انداز ضرر ادامه دهیم.
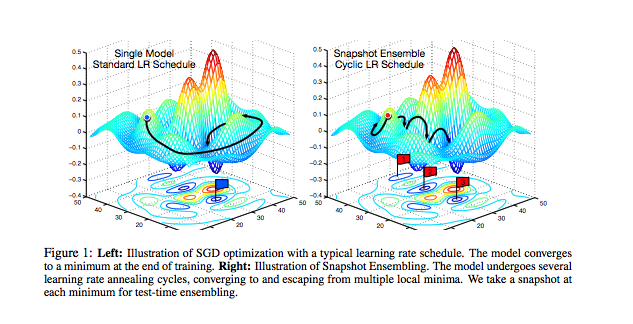
ایده شسته و رفته: با عکس گرفتن از وزنه ها در پایان هر چرخه ، محققان توانستند یک مجموعه از مدل ها را با هزینه آموزش یک مدل واحد بسازند. این امر به این دلیل است که شبکه "بر روی Optima محلی مختلف از چرخه به چرخه" حل می شود ، همانطور که در شکل زیر نشان داده شده است.
پیاده سازی
هر دو یافتن دامنه بهینه از نرخ یادگیری و هم اختصاص برنامه نرخ یادگیری را می توان با استفاده از تماس های برگشتی Keras کاملاً بی اهمیت اجرا کرد.
یافتن دامنه نرخ یادگیری بهینه
ما می توانیم یک تماس تلفنی Keras بنویسیم که ضرر مرتبط با نرخ یادگیری را به صورت خطی متنوع در یک محدوده تعریف شده ردیابی می کند.
تنظیم برنامه نرخ یادگیری
پوسیدگی مرحله برای یک پوسیدگی مرحله ساده ، می توانیم از پاسخ به تماس LeaingRatesCheduler استفاده کنیم.
میزان یادگیری چرخه ای
برای استفاده از تکنیک نرخ یادگیری چرخه ای ، می توانیم این repo را که قبلاً این تکنیک را در مقاله اجرا کرده است ، ارجاع دهیم. در حقیقت ، این repo در پیوست مقاله ذکر شده است.
نزول شیب تصادفی با راه اندازی مجدد
گروه های Snapshot برای اعمال تکنیک "قطار 1 ، دریافت M به صورت رایگان" ، می توانید به این repo مراجعه کنید.
بیشتر خواندن
- Stanford CS231N: آنی سازی نرخ یادگیری
- نرخ یادگیری چرخه ای برای آموزش شبکه های عصبی
- کاوش توپولوژی عملکرد ضرر با نرخ یادگیری چرخه ای
- SGDR: نزول شیب تصادفی با شروع مجدد گرم
- گروه های عکس فوری: قطار 1 ، M را به صورت رایگان دریافت کنید
- (گسترش مفهوم) سطوح ضرر ، اتصال به حالت و گروه سریع DNN ها
بیشتر در علوم داده
درک مکانیسم توجه در مدل های توالی
1 مارس 2023 - 9 دقیقه بخوانیدمدیریت زیرساخت های یادگیری ماشین خود به عنوان کد با Terraform
27 ژوئیه 2022 - 14 دقیقه بخوانیدپیکربندی Terraform: مرجع سریع
27 ژوئیه 2022 - 4 دقیقه بخوانید علم داده هامقدمه ای برای AutoEncoders.
AutoEncoders یک تکنیک یادگیری بدون نظارت است که در آن ما از شبکه های عصبی برای انجام وظیفه یادگیری استفاده می کنیم. به طور خاص ، ما یک معماری شبکه عصبی را به گونه ای طراحی خواهیم کرد که یک تنگنا را در شبکه تحمیل می کنیم که نمایانگر دانش فشرده شده از ورودی اصلی است.
جرمی جردن
جرمی جردن 19 مارس 2018 • 10 دقیقه بخوانید علم داده ها
یادگیری از داده های نامتعادل.
در این پست وبلاگ ، در مورد تعدادی از ملاحظات و تکنیک های مربوط به برخورد با داده های نامتعادل هنگام آموزش یک مدل یادگیری ماشین بحث خواهم کرد. پست وبلاگ برای پیاده سازی تکنیک های مورد بحث به یک بسته مشارکت کننده Sklea به نام Nalbalanced-Lea متکی خواهد بود.
دوره ی فارکس...
ما را در سایت دوره ی فارکس دنبال می کنید
برچسب : نویسنده : مهناز افشار بازدید : 30
